Relational databases support principles of ACID model for reliability and consistency. ACID architectural pattern guarantees that the database transaction executes reliably. 'Isolated' principle states that in case of multiple transactions occurring simultaneously, one transaction shouldn’t see the effects of other in-progress transaction.
Isolation among multiple transactions can be easily achieved with locks. If a session is reading an item, lock can stop another session from modifying the same item and if a session is modifying an item, lock can stop another session from reading the it. It is simple but very costly for a concurrent application. Lock based applications leads to high contention and low concurrency.
To improve concurrency without too many locks, almost all relation database systems and some NoSQL stores such as HBase, use multi-version concurrency control (MVCC) architectural pattern
What is MVCC and how it helps improve concurrency?
MVCC stands for multi-version concurrency control. Whole idea behind MVCC is to improve concurrency of database system by reducing contention and locks.
Readers shouldn’t block writers and writers shouldn’t block reader. MVCC works towards achieving this goal.
In MVCC model, database systems keep multiple versions of same data. So, rather than overwriting an existing data, database engine marks the existing data obsolete and adds a newer version. Database systems use either timestamp or some sort of change identifier to adopt versioning of data. So, with versioning at place, database system can construct a snapshot view of database any given point in time. And every session sees it’s own snapshot view of database.
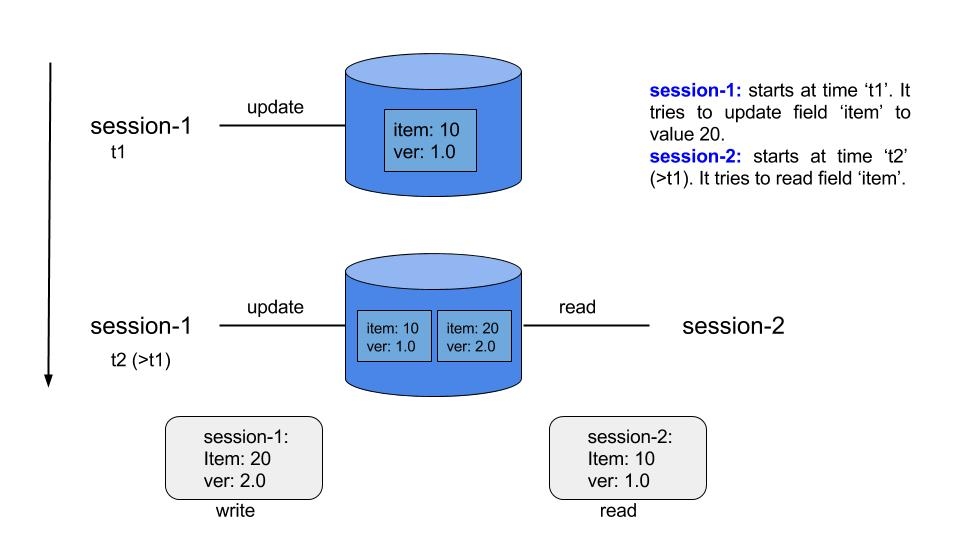 Session 1 and Session 2 are trying to access database field ‘item’.
Session 1 and Session 2 are trying to access database field ‘item’.
Session 1 : update operation starts at time t1
Session 2 : read operation starts at time t2 (>t1)
Session 1 creates another revision of ‘item’, however, Session 2 still reads old revision of ‘item’ as ver:2 was created after Session 1 started.
Points to be noted ...
- No in-place edits of data. Since existing data is never edited, there is no reason to apply a lock. This dramatically improves the performance of database systems.
- Versioning system helps to identify latest revision of data easily.
- Old versions are pruned offline based on how many old versions need to be maintained for the application to work correctly.